虚拟 DOM
通过 React 命令式或声明式语法,创建出来的元素就是虚拟 dom. 根据第一个挂载渲染的结构,生成第一棵虚拟 DOM 树,更新后,生成第二棵 虚拟 DOM 树. 然后比较两个新旧虚拟 DOM 树,找到不同,去修改真实 DOM 树,从而实现代价最小的页面更新
Diff 算法
在之前的第二章中,我们介绍了 React 的命令式语法或声明式语法会生成虚拟 DOM 树(React 元素树). 然后根据新旧两棵虚拟 DOM 树找到不同之后,最终直接以最小代价修改真实 DOM 树. 查找两棵新旧虚拟 DOM 树的算法就是 Diff 算法
Diff 算法有一些通用的解决方案,即生成将一棵树转换成另一棵树的最小操作次数。然而,即使使用最优的算法,该算法的复杂程度仍为 O(n 3 ),其中 n 是树中元素的数量。
如果在 React 中使用该算法,那么展示 1000 个元素则需要 10 亿次的比较。这个开销实在是太过高昂。于是 React 在以下两个假设的基础之上提出了一套 O(n) 的启发式算法:
- 两个不同类型的元素会产生出不同的树;
- 开发者可以通过设置
key属性,来告知渲染哪些子元素在不同的渲染下可以保存不变;在实践中,我们发现以上假设在几乎所有实用的场景下都成立
对比不同类型的元素
React 组件也被视为 React 元素. 所以对比不同类型的元素,不仅局限于
<div></div>这类元素,也包含组件元素
当根节点为不同类型的元素时,React 会拆卸原有的树并且创建新的树。比如,当一个元素从 <a> 变成 <img/>,从 <Article> 变成 <Comment>,或从 <Button> 变成 <div> 都会触发一个完整的重建流程。
当卸载一棵树时,对应的 DOM 节点也会被销毁。组件实例将执行 componentWillUnmount() 方法。当建立一棵新的树时,对应的 DOM 节点会被创建以及插入到 DOM 中。组件实例将执行 componentDidMount() 方法。所有与之前的树相关联的 state 也会被销毁。
在根节点以下的组件也会被卸载,它们的状态会被销毁。比如
// 旧树
<div>
<Counter />
</div>
// 新树
// React 会销毁Counter组件并且重新实例化一个新的Counter。
<span>
<Counter />
</span>对比同一类型的元素
当对比两个相同类型的 React 元素时,React 会保留 DOM 节点,仅比对及更新有改变的属性。比如:
<div className="before" title="stuff" />
<div className="after" title="stuff" />通过对比这两个元素,React 知道只需要修改 DOM 元素上的 className 属性。
当更新 style 属性时,React 仅更新有所更变的属性。比如:
<div style={{color: 'red', fontWeight: 'bold'}} />
<div style={{color: 'green', fontWeight: 'bold'}} />通过对比这两个元素,React 知道只需要修改 DOM 元素上的 color 样式,无需修改 fontWeight。
在处理完当前节点之后,React 继续对子节点进行递归
对比同类型的组件元素
当一个组件更新时,组件实例会保持不变,因此可以在不同的渲染时保持 state 一致。React 将更新该组件实例的 props 以保证与最新的元素保持一致,并调用 componentDidUpdate() 方法。
下一步,调用 render() 方法,diff 算法将在之前的结果以及新的结果中进行递归。
对子节点进行递归
默认情况下,当递归 DOM 节点的子元素时,React 会同时遍历两个子元素的列表;当产生差异时,根据差异修改真实 DOM 树
在子元素列表末尾新增元素时,更新开销比较小。比如:
<ul>
<li>first</li>
<li>second</li>
</ul>
<ul>
<li>first</li>
<li>second</li>
<li>third</li>
</ul>React 会先匹配两个 <li>first</li> 对应的树,然后匹配第二个元素 <li>second</li> 对应的树,最后插入第三个元素的 <li>third</li> 树。
如果只是简单的将新增元素插入到表头,那么更新开销会比较大。比如:
<ul>
<li>Duke</li>
<li>Villanova</li>
</ul>
<ul>
<li>Connecticut</li>
<li>Duke</li>
<li>Villanova</li>
</ul>React 并不会意识到应该保留 <li>Duke</li> 和 <li>Villanova</li>,而是会重建每一个子元素。这种情况会带来性能问题。
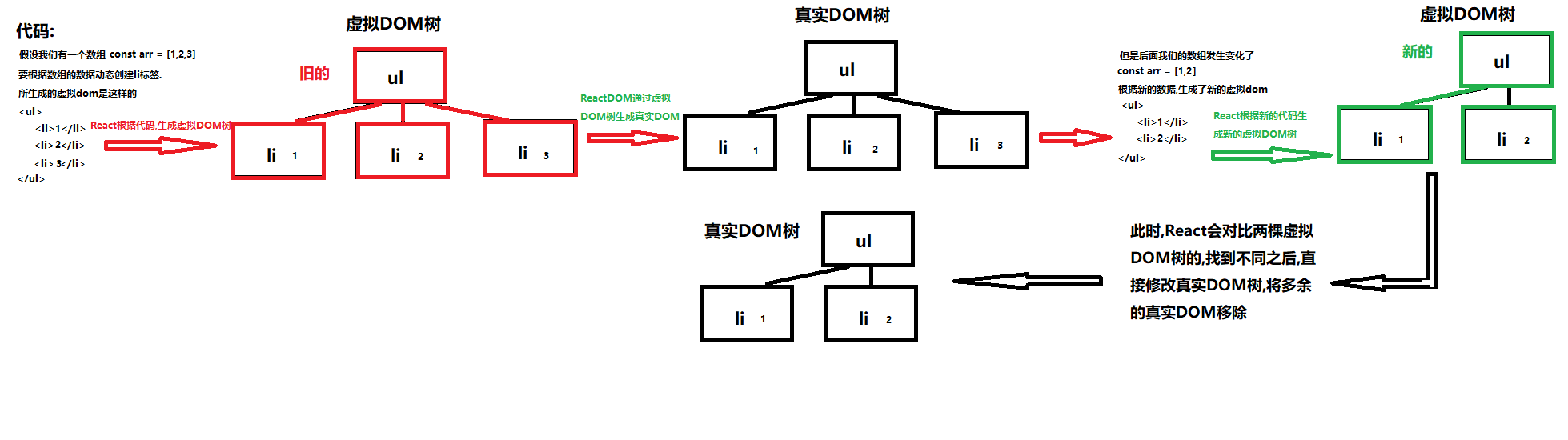
Keys
为了解决上述问题,React 引入了 key 属性。当子元素拥有 key 时,React 使用 key 来匹配原有树上的子元素以及最新树上的子元素。以下示例在新增 key 之后,使得树的转换效率得以提高:
<ul>
<li key="1">Duke</li>
<li key="2">Villanova</li>
</ul>
<ul>
<li key="3">Connecticut</li>
<li key="1">Duke</li>
<li key="2">Villanova</li>
</ul>现在 React 知道只有 key 为 3 的元素是新元素,key 为1,2的元素仅仅移动了。
实际开发中,key 的值只要在当前父元素的范围内 key 值不重复即可. 一般会使用数据中的 id.
<li key={item.id}>{item.name}</li>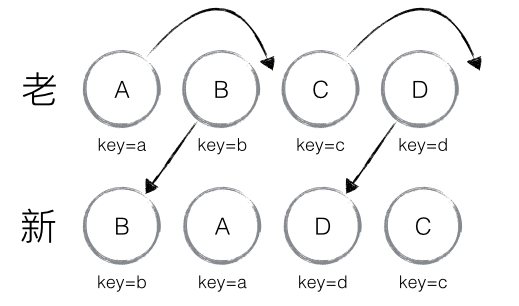
注意: 你也可以使用元素在数组中的下标作为 key.这种方式适合于在元素不再进行重新排序的情况下使用. 如果元素顺序发生变化,则会导致渲染错误。
例如:
import React, { Component } from "react";
export default class App extends Component {
state = {
list: ["html", "css", "js", "react"],
};
render() {
const { list } = this.state;
return (
<>
<button
onClick={() => {
// 点击按钮之后,将新数据添加到数组的开头,会导致重新渲染之后,元素顺序发生变化
const newList = [...list];
newList.unshift("jsx");
this.setState({
list: newList,
});
}}
>
按钮
</button>
<ul>
{list.map((item, index) => {
return (
// 使用index下标作为key的值
<li key={index}>
<span>{item}</span>
<input type="text" />
</li>
);
})}
</ul>
</>
);
}
}总结
在当前的实现中,一棵子树能在其兄弟之间移动,但不能移动到其他位置。例如,下面的这种情况. React 并不会改变 A 树的位置,而是拆除 A 树,在 D 节点下重新创建 A 树.实际开发中应避免这样的操作,不过目前的开发中基本没有这种情况
该算法不会尝试匹配不同组件类型的子树。如果你发现你在两种不同类型的组件中切换,但输出非常相似的内容,建议把它们改成同一类型。
Key 应该具有稳定,可预测,以及列表内唯一的特质。不稳定的 key 会导致许多组件实例和 DOM 节点被不必要地重新创建或渲染错误,这反而导致了性能下降